DArT Bulk Loading
From ICISWiki
Contents |
Introduction
DArT data is usually large that the ICIS workbook cannot accommodate loading such datasets. DArT datasets comes in a matrix format. More information on DArT datasets on ICIS can be found here. Since DArT datasets have very similar data formats, a small java code was created to transform the matrix format into data files which can be loaded to MySQL as batch files.

Steps in Loading Large DArT datasets
Get GIDs used in the Dataset
If the CID and SID comes with the dataset, corresponding GID for the CID and SID pair is retrieved from the GMS database. If there is no CID and SID given for the dataset, GID is requested from UQ.
Transform DArT datasets
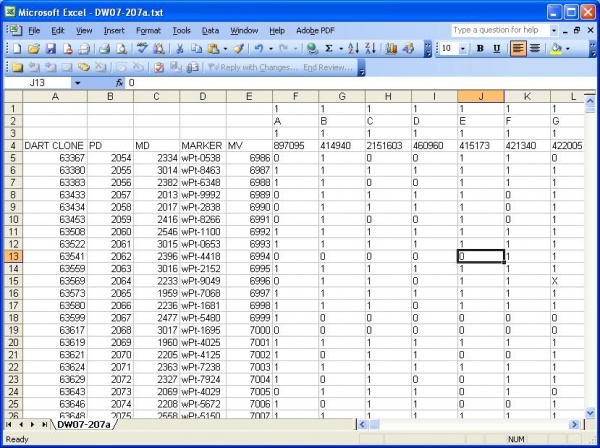
The Dataset is transformed into a format similar to the workbook format for loading small DArT datasets. The first few columns are reserved for the factor values (Dart Clone, PDID, MDID, Marker).
Getting the Marker ID (MD or MDID)
- Each DArT clone is treated as a the Marker Detector. Each clone will have a marker name assigned by Triticart. If a clone does not have a name assigned by Triticarte, a name will be assigned to it using "TC" appended by the cloneID.
- For example: A clone ID = 10000 will be assigned a clone name = TC10000
- After populating the Marker column,the MD and PD columns will be populated by the Marker ID and PDID values retrieved from the GEMS database using the ICIS workbook Get Marker ID tool. A new marker ID is assigned to MDID if the marker name does not exist in the database.
Assigning MV NAMES
- The name of the Molecular Variant is the same as the Marker Detector but will have a different MVID since the MVID is retrieved from the GEMS database.
MV STATE Values
- The STATE has values + for present, - for absent, * for missing. These correspond to the 0, 1 and X data from Triticart.
Summary Data
- Summary data like Callrate, PIC and Q were not included in the Dataset loading. Summary Data can be loaded as a different dataset.
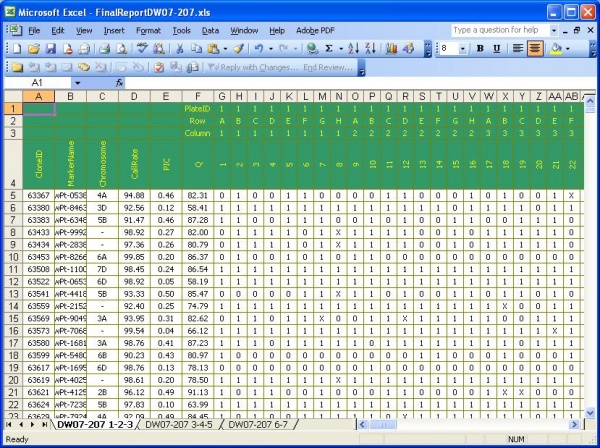
From the original format:
Data is transformed to this format:
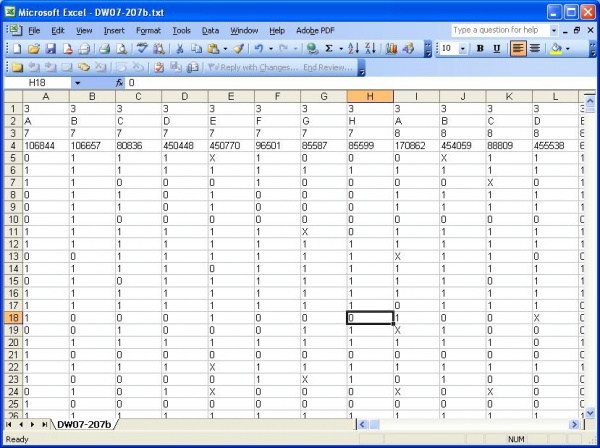
Format for the succeeding worksheets
If there are more than one worksheet, do not include the factor columns for the succeeding worksheets.
Save worksheets as text files
Save the worksheet/s into a single folder. Make sure that the filename for the worksheet with factor values comes first. A macro was created to save all worksheets for a given dataset into a single folder.
Execute java code for uploading DArT
A simple java code was used to create files which can be executed in mysql as batch files. Since most of the data is stored in the data_c, data_n and oindex tables, a file is created for each of these tables. Data for all the other tables are stored in the study.sql file.
- Study.sql - this file contains insert statements for DMS tables: study, factor, effect,level_n, level_c , veffect and variate tables
- datac.sql - this file is used to load data into the data_c table
- datan.sql - this file is used to load data into the data_n table
- oindex.sql - this file is used to load data into the oindex tables
Load Data to MySQL
To load the Study.sql file into the database:
mysql prompt> source <path to file>;
In MySQL, loading of bulk data is faster using the load data syntax. The datac, datan and oindex sql files do not have insert statements. They contain comma delimited data for data_c, data_n and oindex tables. To load data from this three files:
mysql prompt> load data infile <path to file> into fields terminated by ',';

